Welcome to the the fifth post in our blog series “Forget Everything You know about VDI.” The previous four topics we’ve addressed – performance, why move to the public cloud, deployment simplicity, and massive scalability (in minutes!) are complete game changers in their own right, but taken together, they are nothing less than transformational for enterprises. New-found agility – to instantly shift to remote working, pursue new business opportunities, and reallocate critical IT resources – is the primary reason. Our final topic this week, operational simplicity, has huge implications for IT budgets. Suddenly, if your IT team doesn’t have to micro-manage legacy VDI or spend vast amounts of time on PC updates, patches, and refresh cycles, what would you do with all that extra time and money?
The Most Mission Critical Enterprise Workload
When you think about it, desktops are more mission critical than any other workload in the data center – more than SAP, Exchange, and other enterprise apps. If SAP is down, your users cannot access SAP for a time, but they can continue to be productive by switching gears and working on something else. However, if users virtual desktops are unavailable, they can’t just move on to another task; if their virtual desktop is down, productivity plummets to zero. That’s not a risk you want to take, and yet, our customers repeatedly tell us that they have to spend too much time just keeping their legacy VDI solutions up and running. CIOs tell us they need an alternative to the VDI “babysitting” that takes up so many valuable resources.
Legacy VDI is Complex & Expensive to Operate

Most of the cost of legacy VDI stems from day-to-day operations. All of this complexity requires an organization to commit multi-function, level 2 / level 3 IT skill sets to operate their VDI infrastructure. The litany of day to day challenges when users cannot connect or are experiencing poor performance demands ongoing troubleshooting by these valuable people to continually address server, storage, virtualization, networking, and end point issues. In an attempt to get in front of these issues, companies often use third party monitoring tools to diagnose and troubleshoot user issues. The challenge is that these third party tools can’t always access the systems where issues are occurring; they are limited by how observable all of the underlying systems are.
All of these challenges are exacerbated by the complexity of upgrading all the different components of the VDI infrastructure, including clients, agents, brokers, databases, load balancers, gateways, virtualization, servers, storage, networking, licensing servers, guest operating system & more. Phew! Your IT team better have strong change-management techniques, because an upgrade of any of these components can cause unforeseen problems that typically require multiple, expensive people to unravel!
Even if your IT team is used to all the legacy VDI babysitting, why would you want to spend time and money that way? Your IT people can contribute to the business in much more valuable ways.
Workspot Cloud PC Simplicity Lowers TCO
At first glance, you’d think that “enterprise-simplicity” is an oxymoron. Large enterprises have all types of users, and the business has existing processes, security policies, regulatory obligations and other unique requirements. We built our turnkey, SaaS cloud PC platform with simplicity for enterprise operation as our mission, so the total cost of ownership goes down and overall value to the business goes up. Forget about the operational complexity and expense of legacy VDI. When we talk about “turnkey”, we mean that we are responsible not only for ensuring “go-live” success, but also for continually upgrading the service, with upgrades typically happening every 6-8 weeks. All of these updates are immediately available to all of our customers. Your IT team doesn’t have to spend one more minute grappling with virtual desktop infrastructure upgrades. Most of our customer-facing components auto-upgrade, however, some of our customers choose to retain control over the Workspot Client updates so they can orchestrate that process with their users.
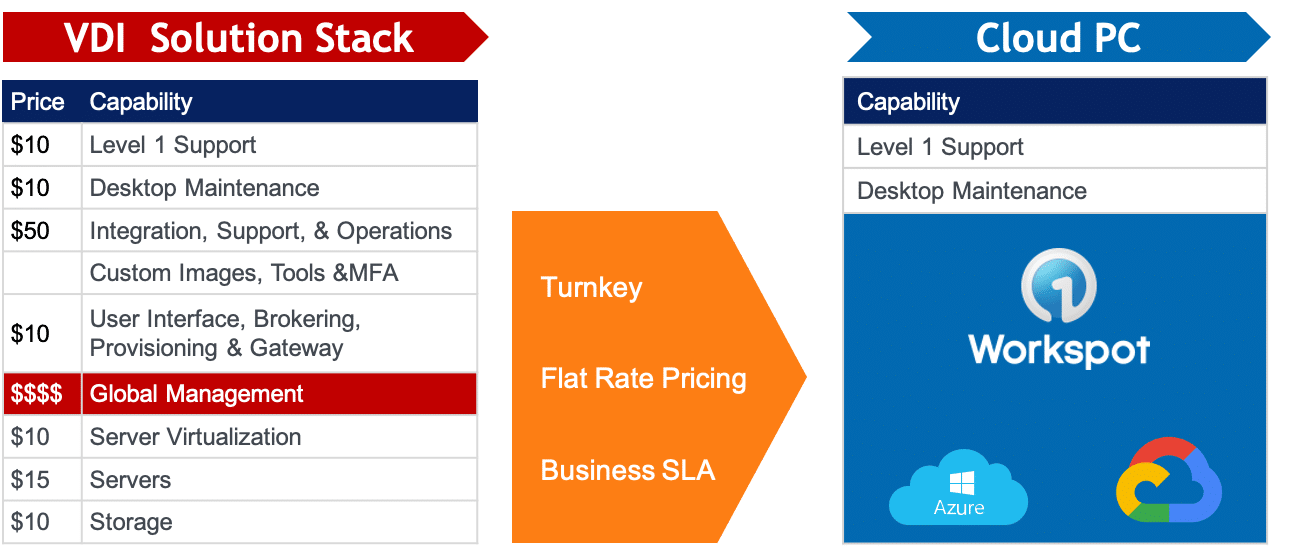
Legacy VDI complexity is history; Workspot eliminates it with our turnkey, enterprise-proven
SaaS cloud PC platform on Azure and Google Cloud.
We are focused on delivering simplicity – simple to deploy, simple to scale and simple to operate. But behind the scenes there are multiple components that need to be coordinated in order to deliver our cloud PC service with the very best reliability and high-availability. The diagram below represents an end user using Workspot Client running on their endpoint-of-choice (Windows PC, Mac, iOS, Android, Linux), to connect over a network (WiFi, Cellular), to a public cloud (Azure and/or Google Cloud) to any of the dozens of cloud regions available from Azure or Google Cloud, the connection then traverses a gateway to a Windows 10 cloud PC running the Workspot Agent. The cloud PC itself may be connected through S2S networking to the corporate data center.
We have made it simple for a customer to deploy and scale their users onto this architectural framework, and we are focused on making sure that the user connections are both reliable and performant.

Our mission for enterprise-simplicity shields IT teams from the underlying cloud PC service components, while also allowing themcontrol over their implementation. Workspot is responsible for reliability, high-availability, and easy scalability.
Three Areas of Operational Simplicity
We focus on three primary areas for achieving operational simplicity:
- Architect the product for high availability so the users can connect to their cloud PCs reliably.
- Collect data in real-time about usage, security events, and errors from all the service components involved in the delivery of a cloud PC experience.
- Focus on pro-active mitigation, which includes resolving a problem fast, and understanding and mitigating the impact of a problem across more users or more customers.

Workspot’s turnkey service shields system complexity from IT teams, while also
enabling them to stay in full control of their implementation.
Learning Cycle to Continuously Improve Operational Simplicity
The key to continuously improving operational simplicity for our customers is a tight learning cycle we have established between our customers, our customer-facing teams and our product teams. Every time we see a problem at any of our customers, we ask ourselves the following questions:
(a) Did we see the problem before it happened? If not, what do we need to do to either prevent it from happening (architecture) or see the problem through instrumentation.
(b) If we saw the problem, did we have all the information needed to quickly diagnose the problem ourselves? If not, what instrumentation needs to be added to the product so that we can conduct the root-cause analysis in real-time?
(c) Were we able to limit the impact of the problem to the smallest number of users possible? Are the right procedures in place to do so?
Product Architected for High Availability
Some of the critical architectural features that deliver high availability are:
(1) Our Control Plane is not in the Critical Path: Our control plane has 99.99+% reliability, but in the event that it is unavailable, we want to make sure that the user is still able to connect to their cloud PC. For 95% of our use cases, a user is able to connect to their cloud PC even if Workspot Control is unavailable.
(2) Backup & Restore: Each cloud PC can be configured for two scheduled backups. IT can quickly restore any individual cloud PC to one of the backups.
(3) Regional Disaster Recovery: For customers who want the highest level of availability, we offer cloud region disaster recovery which enables a cloud PC to be restored in minutes in a different region of the public cloud, should their primary region become unavailable for any reason.
Real-Time Data for Visibility
We collect a lot of data about everything that goes in our systems:
(1) Network Operations Center: Our customer support team monitors all user access in real-time using our Network Operations Center. We want to be aware of any challenges in access – unavailability or poor performance.
(2) Security Events: We collect real-time security data about user access, configuration changes and other events. These security events can be pulled via APIs into the customer SIEM tools, such as Splunk.
(3) Usage: Many of our customers are interested in understanding what end users are doing within their cloud PCs.
Pro-Active Mitigation
Once we notice there is a problem, our customer support teams are focused on two key areas:
(1) Fast Time to Resolution: How do we resolve the problem quickly? In the vast majority of cases, the problem is due to something that is outside our control; perhaps IT upgraded the cloud PC image, or the network that the user is connected to went down, or the infrastructure in the public cloud region was updated and encountered a glitch. In rare cases, an entire cloud region has gone down. If it’s a problem that was caused by something we did – a client update or control plane update – then we want to fix the problem as quickly as possible.
(2) Impact Analysis: Once we see a problem, we want to understand whether it affects one user, all the users in a certain region for one customer, all the users across customers in one region, or all customers. Once our customer support team can understand the impact of the problem, our goal is to pro-actively warn the potentially affected customers.
Our mission for enterprise operational simplicity has dramatically transformed end user computing for our customers. We are absolutely committed to your success, and we have the technology, and the team to make that happen for you! Ready to learn more? Schedule a demo and let’s discuss how Workspot can meet your complex requirements while simplifying your world.




